DynamoDB errors: handle with care! (pt 2)
Retries, idempotency, exactly-once processing and your data integrity.

In part 1 of this blog, we looked at some of the error handling challenges for clients connecting over a network to databases. We learned that when retries are involved, idempotency is a good property to have - but it doesn't automatically ensure that the application intents are processed only once, or in the order desired. Here in part 2, we'll talk about a DynamoDB behavior that catches a few developers unawares, and then we'll talk about some options for adding safety around a lot of data operations to get assurances around data integrity with DynamoDB.
What makes DynamoDB so different, anyway?
The information above about possible outcomes from a request to store a change assumes that the client is talking directly to the database - and for many, that has been the reality of their experience. The client connects to the writer node for a relational database, and those three possibilities (success, fail, timeout) are what need to be handled by the developer. But when your client is talking to DynamoDB, it is not actually connected directly to that writer/leader replica of the data. The client is connected via a proxy called a "Request Router".
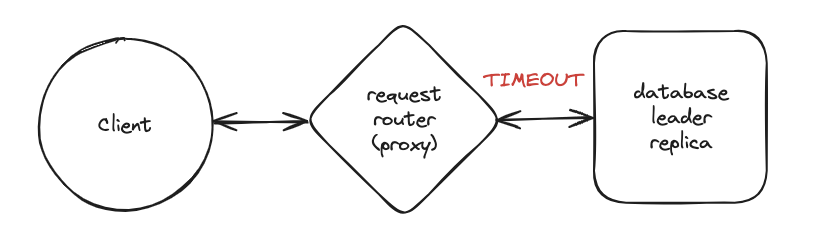
It's worth noting that this proxy arrangement is not peculiar to DynamoDB - you see connection poolers and similar in other databases - and there are more distributed relational databases gaining traction in the market these days too (with their own intelligent proxy layer). Here's the key point to observe - if there is a timeout for a request between the proxy and the backing database replica, how will this manifest in the result seen by the client? The proxy does not want to wait forever, so it will give up at some point - and then there is no point keeping the client waiting. In DynamoDB, the proxy (request router) will respond to the client with a 500-level response code - essentially looking the same as a "your request failed and the mutation was not applied" response. But, the change may in fact have already been applied. That's right - unlike other database systems you may have worked with in the past, an error response might actually mean that the write was successful! You should treat system error responses just as you would a timeout.
If you want to be sure that your change was applied in DynamoDB, you must typically keep retrying until you get a success (200-level) response code. If your client sees a timeout or a system error, there is often no way to know if the change was applied or not.
'Tis a lesson you should heed:
Try, try, try again.
If at first you don't succeed,
Try, try, try again.
- Edward Hickson
There are some exceptions. If you can be absolutely certain that there are no other threads that could be writing changes to the same items in your DynamoDB table, and you know the state of that item prior to your attempted write, you can make a consistent read of that item to see if your change was applied. An example might be a workflow which inserts a new item with a UUID as the key - if the request response is an error, you can just go read the item at that UUID key to see if it is present and thus determine whether the write succeeded. This assumes that you are comfortable with the statistical improbability of UUID collision!

DynamoDB SDK default behavior
Be aware that the DynamoDB SDKs automatically retry on 500 level error responses by default. It's important to keep this in mind, particularly if you are making use of non-idempotent operations like the atomic counter pattern. Depending on the use case, you might want to think about customizing this configuration - at least for non-idempotent writes. You may not even be aware of the retries, as generally only the status of the final attempt is reported in logs etc. Most errors in DynamoDB are transient - lasting perhaps a few seconds, so the retries will eventually find success.
For operations which should be retried, how long should you go on retrying? As long as it takes - or as long as you can stand, and then you'll need to figure out what it means and how to deal with this exceptional situation. When I was a kid riding around in the back of my father's car anxious to be done with his errands and move on to the destination I was interested in, I would ask "how long, Dad?". He would answer by posing another question: "how long is a piece of string?" This would drive me crazy! So, I apologize for giving you effectively the same answer on DynamoDB retries.
Making it easier to keep things tidy
We've seen that using idempotent operations in DynamoDB tends to keep things simpler - use them preferentially wherever you can. We've also seen that conditional writes can enforce some constraints to maintain correctness and concurrency control (think optimistic locking, and multi-version concurrency control). And, we've seen that recording a unique identifier for each applied application intent can help to ensure exactly-once processing (paired with a condition on that identifier not having been applied before). Is there a way we can accomplish this for additional updates to an existing item? Yes, and here is how...
For each step that changes an item, add a unique identifier for that intent to the item itself, and include in the condition expression a check to make sure that identifier is not already present. A clean way to accomplish this would be to store these change identifiers in a set attribute - because sets can easily be added to and they maintain a list of unique elements - they can also be searched for presence of an identifier using the "contains" operator in the condition expression. Let me give you a quick (JavaScript) example - in this case we have a non-idempotent operation (atomic increment of a counter). Perhaps we are processing workflows with steps from a queue - each step increments the counter, but we don't want to have any retries causing overcounting. So we maintain a string set with UUIDs to log each successful update - and we check it each time to be sure we're not reapplying a change intent.
function createUpdateItemInput() {
return {
"TableName": "ex1p",
"Key": {
"p": {
"S": "process257"
}
},
"ReturnConsumedCapacity": "TOTAL",
"UpdateExpression": "SET #a6400 = #a6400 + :a6400 ADD #a6401 :a6401",
"ConditionExpression": "NOT (contains(#a6402, :a6402))",
"ExpressionAttributeValues": {
":a6400": {
"N": "1"
},
":a6401": {
"SS": [
"f9485b28-5cbb-4b96-9717-1e8edf8ee3f5"
]
},
":a6402": {
"S": "f9485b28-5cbb-4b96-9717-1e8edf8ee3f5"
}
},
"ExpressionAttributeNames": {
"#a6400": "counter",
"#a6401": "changes",
"#a6402": "changes"
}
}
}
The above UpdateItem operation can safely be retried as many times as you like - the change will only be applied once! This can be a very workable pattern for items which have a known lifecycle that includes a limited number of updates. It is not a good choice when the number of updates in the life of an item is large (or even unbounded). This is because that string set is going to grow and grow, eventually causing each update to become quite costly in write unit consumption because of the item size - and you could also run into the ~400KB item size limit.
Yep - I'm going to retry the "next time" thing...
I'm trying to keep each of my blogs bite-size. Looking at what we've covered so far and knowing what's ahead, I think this is a good point to take a break. So step away for a few minutes and think over what we've covered so far. See you in part 3, where we'll look at the game-changer that is DynamoDB Transactions.



